% ![]()
Introduction
SlunkCrypt is an experimental cross-platform cryptography library and command-line tool. A fully-featured GUI is provided for the Windows platform.
Please refer to the section encryption algorithm for more details!
For news and updates, please check out the official SlunkCrypt project web-site at: https://lord_mulder.gitlab.io/slunkcrypt/
Legal Warning
Use of SlunkCrypt may be illegal in countries where encryption is outlawed. We believe it is legal to use SlunkCrypt in many countries all around the world, but we are not lawyers, and so if in doubt you should seek legal advice before downloading it. You may find useful information at cryptolaw.org, which collects information on cryptography laws in many countries.
System Requirements
The SlunkCrypt library and the command-line application currently run on the following platforms:
- Microsoft Windows (Windows XP SP-3, or later) — i686, x86-64 and ARM64
- Linux (kernel version 3.17, or later) — i686, x86-64, ARM64 and MIPS
- Various BSD flavors (tested on NetBSD 9.2, FreeBSD 13.0 and OpenBSD 7.0) — i686 and x86-64
- Solaris (tested on Solaris 11.4 and OmniOS/illumos) — i686 and x86-64
- GNU/Hurd (tested on Debian GNU/Hurd 0.9) — i686
- Haiku (tested on Haiku R1/b3) — i686 and x86-64
- Mac OS X (tested on “Big Sur”) — x86-64 and ARM64
The SlunkCrypt GUI application currently runs on the following platforms:
- Microsoft Windows with .NET Framework 4.7.2 — can be installed on Windows 7 SP1, or later
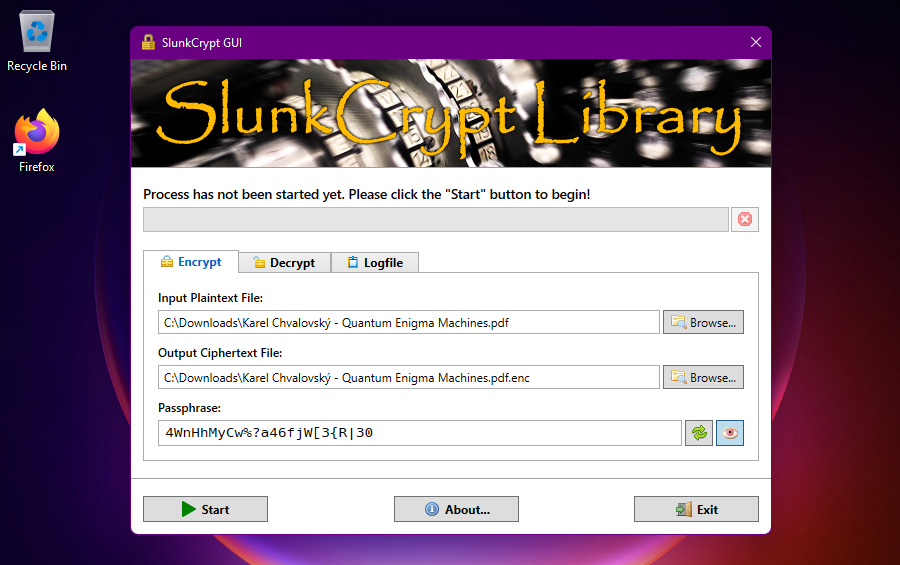
GUI Usage
This is how the graphical user interface (GUI) for SlunkCrypt looks on Windows 11:
{kind=link}
Prerequisites
Please be sure to install the .NET Framework 4.7.2, or any later .NET Framework 4.x version, before running the SlunkCrypt Windows GUI application:
https://dotnet.microsoft.com/download/dotnet-framework
Note: If you are running Windows 8.1 or later, then almost certainly a suitable version of the .NET Framework is already installed 😎
Settings
The following settings can be adjusted in the slunkcrypt-gui.exe.config configuration file:
-
DisableBusyIndicator:
If set totrue, the “busy indicator” animation will be disabled on application startup — default value:false. -
ThreadCount:
Specifies the number of worker threads to use — default value:0(i.e. detect the number of available processors and create one thread for each processor). -
KeepIncompleteFiles:
If set totrue, incomplete or corrupted output files will not be deleted — default value:false. -
LegacyCompat:
If set to1, show options to enable “legacy” compatibility-mode in the GUI; if set to2, select “legacy” compatibility-mode by default — default value:0.
Command-line Usage
This section describes the SlunkCypt command-line application.
Synopsis
The SlunkCypt command-line program is invoked as follows:
slunkcrypt --encrypt [pass:<pass>|file:<file>] <input.txt> <output.enc>
slunkcrypt --decrypt [pass:<pass>|file:<file>] <input.enc> <output.txt>
slunkcrypt --make-pw [<length>]
Commands
One of the following commands must be chosen:
--encrypt(-e):
Run application in encrypt mode. Reads the given plaintext and generates ciphertext.--decrypt(-d):
Run application in decrypt mode. Reads the given ciphertext and restores plaintext.--make-pw(-p):
Generate a "strong" random passphrase, suitable for use with SlunkCrypt.--self-test(-t):
Run the application in self-test mode. Program will exit after all test are completed.
Options
The following command-line options are available:
pass:<pass>:- Specifies the "secret" passphrase directly on the command-line. This is considered insecure.
file:<file>:- Specifies a file to read the passphrase from. Only the first line of the file will be read!
- Note: It is also possible to specify
-in order to read the passphrase from the stdin.
<input>:- In encrypt mode – specifies the plaintext file (unencrypted information) that is to be encrypted.
- In decrypt mode – specifies the ciphertext file (result of encryption) that is to be decrypted.
<output>:- In encrypt mode – specifies the file where the ciphertext (result of encryption) will be stored.
- In decrypt mode – specifies the file where the plaintext (unencrypted information) will be stored.
<length>:- Specifies the length of the passphrase to be generated. If not specified, defaults to 24.
Remarks
-
The same passphrase must be used for both, encrypt and decrypt mode. The decryption of the ciphertext will only be possible, if the "correct" passphrase is known. It is recommended to choose a "random" password that is at least 12 characters in length and consists of a mix of upper-case characters, lower-case characters, digits as well as special characters.
-
Passing the passphrase directly on the command-line is insecure, because the full command-line may be visible to other users!
Environment
The following environment variables may be used:
-
SLUNK_PASSPHRASE:
Specifies the "secret" passphrase. This environment variables is only evaluated, if the passphrase was not specified on the command-line.
Passing the passphrase via environment variable is considered more secure, because environment variables are not normally visible to other (unprivileged) users. -
SLUNK_KEEP_INCOMPLETE:
If set to a non-zero value, incomplete or corrupted output files will not be deleted automatically. By default, the files will be deleted. -
SLUNK_THREADS:
Specifies the number of worker threads to use. By default, SlunkCrypt detects the number of available processors and creates one thread for each processor. -
SLUNK_LEGACY_COMPAT:
If set to a non-zero value, enables “legacy” compatibility-mode, required to decrypt files encrypted with SlunkCrypt version 1.2.x or older. -
SLUNK_DEBUG_LOGGING:
If set to a non-zero value, enables additional logging output to the syslog (Unix-like) or to the debugger (Windows). This is intended for debugging purposes only!
Examples
Here are some examples on how to use the SlunkCrypt command-line application:
Example #1
-
Let's generate a new random (secure) password first:
slunkcrypt --make-pwExample output:
cdG2=fh<C=3[SSCzf[)iDjIV -
Now, encrypt the plaintext message, using the generated password:
slunkcrypt --encrypt pass:"cdG2=fh<C=3[SSCzf[)iDjIV" plaintext.txt ciphertext.encOptionally, let's have a look at the ciphertext:
hexdump -C ciphertext.enc -
Finally, decrypt the ciphertext, using the same password as before:
slunkcrypt --decrypt pass:"cdG2=fh<C=3[SSCzf[)iDjIV" ciphertext.enc plaintext.outOptionally, verify that the decrypted file is identical to the original:
sha256sum -b plaintext.txt plaintext.out
Example #2
-
Generate a new password and store it to a text file:
slunkcrypt --make-pw > passwd.txtOptionally, output the generated password to the terminal:
cat passwd.txt -
Encrypt file by reading the password from the text file:
slunkcrypt --encrypt file:passwd.txt plaintext.txt ciphertext.enc
Example #3
-
Generate a new password directly to an environment variable:
MY_PASSWD="$(slunkcrypt --make-pw)"Optionally, output the generated password to the terminal:
echo "${MY_PASSWD}" -
Encrypt file by reading the password from the stdin:
slunkcrypt --encrypt - plaintext.txt ciphertext.enc <<< "${MY_PASSWD}"
Encryption algorithm
SlunkCrypt is based on concepts of the well-known Enigma machine, but with significant improvements, largely inspired by Ross Anderson – “A Modern Rotor Machine”.
A great explanation and visualization of how the original Enigma machine works can be found in this video.
Overview
This section summarizes the improvements that have been implemented in SlunkCrypt:
-
The original Enigma machine had only three (or, in some models, four) rotors, plus a static "reflector" wheel. In SlunkCrypt, we uses 256 simulated rotors for an improved security. Furthermore, the original Enigma machine supported only 26 distinct symbols, i.e. the letters
AtoZ. In SlunkCrypt, we use 256 distinct symbols, i.e. the byte values0x00to0xFF, which allows the encryption (and decryption) of arbitrary streams of bytes, rather than just plain text. Of course, SlunkCrypt can encrypt (and decrypt) text files as well. -
In the original Enigma machine, the signal passes through the rotors twice, once in forward direction and then again in backwards direction – thus the "reflector" wheel. This way, the Enigma's encryption was made involutory, i.e. encryption and decryption were the same operation. While this was highly convenient, it also severely weakened the cryptographic strength of the Enigma machine, because the number of possible permutations was reduced drastically! This is one of the main reasons why the Enigma machine eventually was defeated. In SlunkCrypt, the signal passes through the simulated rotors just once, in order to maximize the number of possible permutations. This eliminates the most important known weakness of the Enigma machine. Obviously, in SlunkCrypt, separate "modes" for encryption and decryption need to be provided, since encryption and decryption no longer are the same operation.
-
In the original Enigma machine, the rightmost rotor was moved, by one step, after every symbol. Meanwhile, all other rotors were moved, by one step, only when their right-hand neighbor had completed a full turn – much like the odometer in a car. The fact that most of the rotors remained in the same "static" position most of the time was an important weakness of the Enigma machine. Also, the sequence of the Enigma's rotor positions started to repeat after only 16,900 characters. SlunkCrypt employs an improved stepping algorithm, based on a linear-feedback shift register (LSFR), ensuring that all rotors move frequently and in a "randomized" unpredictable pattern. The rotor positions of SlunkCrypt practically never repeat.
-
The internal wiring of each of the original Enigma machine's rotors was fixed. Each rotor "type" came with a different internal wiring (i.e. permutation). Some models had up to eight rotor "types" to choose from, but only three or four rotors were used at a time. Nonetheless, the internal wiring (i.e. permutation) of each of the supplied rotors was not modifiable. This severely restricted the key space of the Enigma machine, as far as the rotors are concerned, because only the order of the rotors and the initial position of each rotor could be varied. In SlunkCrypt, a fully randomized wiring (i.e. permutation) is generated from the passphrase for each of the 256 simulated rotors. The initial rotor positions are randomized as well.
-
SlunkCrypt does not currently implement the plugboard (“Steckerbrett”). Even though the plugboard significantly contributed to the key space of the original Engima machine, it was simply a fixed substitution cipher. SlunkCrypt already has a much bigger key space than that of the original Engine machine, because the number of rotors is substantially larger and because the internal wiring of these rotors is completely key-dependant. Therefore, adding a plugboard would not contribute notably to SlunkCrypt's cryptographic strength.
Details
This section explains some crucial implementation details of the SlunkCrypt library:
-
DRBG: The deterministic random bit generator (DRBG) employed by SlunkCrypt is called Xorwow, an enhanced variant of Xorshift , i.e. a form of linear-feedback shift registers (LSFR).
-
Initialization (key schedule): In the initialization phase, the pseudo-random internal wiring (i.e. permutation) is generated – separately for each of the 256 rotors. For this purpose, the initial state of the DRBG is set up in a way that depends on the given passphrase, a message-specific nonce as well as the current rotor index. More specifically, the initial state of the DRBG is derived from a combination of all input parameters, by applying a large number of iterations of the FNV‑1a 128-Bit hash function. The permutation for the current rotor is then created by the Fisher‑Yates shuffle algorithm, using the DRBG as its randomness source. This produces a distinct "randomized" internal rotor wiring for each message to be encrypted.
-
Message processing: During the encryption or decryption process, the individual offsets (positions) of the first 8 rotors are controlled by a 64-Bit counter, whereas the offsets of the remaining 248 rotors are continuously "randomized" by the DRBG. The initial counter value as well as the initial state of the DRBG are set up in a way that depends on the given passphrase and a message-specific nonce. Also, after each symbol that was processed, the counter is incremented by one and new pseudo-random offsets (rotor positions) are drawn.
-
Checksum: The message-length is padded to a multiple of 8 bytes and a 64-Bit BLAKE2s hash is appended, before encryption. This "checksum" can be used to detect decryption errors.
Programming Interface (API)
This section describes the SlunkCypt library interface for software developers.
Getting started
In order to use the SlunkCypt library in your C++ code, include <slunkcrypt.hpp> header and instantiate the appropriate SlunkCypt classes:
Example #1
Here is a simple example on how to use the SlunkCrypt Encryptor class:
#include <slunkcrypt.hpp>
#include <fstream>
#include <iostream>
int main()
{
/* Open input and output files here */
uint8_t buffer[BUFF_SIZE];
slunkcrypt::Encryptor slunk_encrypt(passphrase);
while (input.good())
{
input.read(reinterpret_cast<char*>(buffer), BUFF_SIZE);
if ((!input.bad()) && (input.gcount() > 0))
{
if (!slunk_encrypt.inplace(buffer, (size_t)input.gcount()))
{
/* Implement error handling here */
}
output.write(reinterpret_cast<char*>(buffer), count);
}
}
std::cout << std::hex << slunk_encrypt.get_nonce() << std::endl;
}
Example #2
Here is a simple example on how to use the SlunkCrypt Decryptor class:
#include <slunkcrypt.hpp>
#include <fstream>
#include <iostream>
int main()
{
/* Open input and output files here */
uint8_t buffer[BUFF_SIZE];
slunkcrypt::Decryptor slunk_decrypt(passphrase, nonce);
while (input.good())
{
input.read(reinterpret_cast<char*>(buffer), BUFF_SIZE);
if ((!input.bad()) && (input.gcount() > 0))
{
if (!slunk_decrypt.inplace(buffer, (size_t)input.gcount()))
{
/* Implement error handling here */
}
output.write(reinterpret_cast<char*>(buffer), count);
}
}
}
C++11 API
This section describes the "high-level" C++11 API of the SlunkCrypt library. All SlunkCrypt classes live in the slunkcrypt namespace.
Encryptor
Class for encrypting data using the SlunkCrypt library.
Constructor
Create and initialize a new Encryptor instance. Also generated a new, random nonce.
Encryptor::Encryptor(
const std::string &passwd,
const size_t thread_count = 0U,
const bool legacy_compat = false,
const bool debug_logging = false
);
Parameters:
-
passwd
The password to "protect" the message. The password is given as anstd::string, e.g. UTF-8 encoded characters. The same password may be used to encrypt multiple messages. Also, the same password must be used for both, encryption and decryption; it will only be possible decrypt the ciphertext, if the "correct" password is known. The password must be kept confidential under all circumstances!Note: In order to thwart brute force attacks, it is recommended to choose a "random" password that is at least 12 characters in length and that consists of upper-case characters, lower-case characters, digits as well as other "special" characters.
-
thread_count
Specifies the number of worker threads to use (optional). By default, SlunkCrypt detects the number of available processors and creates one thread for each processor. -
legacy_compat
Enables "legacy" compatibility-mode; required to encrypt messages in a way that allows decryption with SlunkCrypt version 1.2.x or earlier. Option is disabled by default. -
debug_logging
Enables additional debug logging. Messages are written to the syslog (Unix-like) or to the debugger (Windows). Option is disabled by default.
Exceptions:
- Throws
std::runtime_error, if the nonce could not be generated, or if the SlunkCrypt context could not be allocated.
Encryptor::process() [1]
Encrypt the next message chunk, using separate input/output buffers.
bool process(
const uint8_t *const input,
uint8_t *const output,
size_t length
);
Parameters:
-
input
A pointer to the input buffer containing the next chunk of the plaintext to be encrypted. The plaintext is given as a byte array (uint8_t). This can be arbitrary binary data, e.g. UTF-8 encoded text. NULL bytes are not treated specially.The input buffer must contain at least
lengthbytes of data. If the buffer is longer thanlengthbytes, then only the firstlengthbytes will be processed and the remainder is ignored! -
output
A pointer to the output buffer where the ciphertext chunk that corresponds to the given plaintext chunk will be stored. The ciphertext is stored as a byte array (uint8_t); it has the same length as the plaintext data.The output buffer must provide sufficient space for storing at least
lengthbytes of encrypted data. If the buffer is longer thanlengthbytes, then only the firstlengthbytes of the buffer will be filled with encrypted data! -
length
The length of the plaintext chunk contained in the input buffer given by theinputparameter, in bytes. At the same time, this determines the minimum required size of the output buffer given by theoutputparameters, in bytes.Note: It is recommended to process chunks of at least ∼64 KB each, in order to take full advantage of multi-threading.
Return value:
- If successful,
trueis returned; otherwisefalseis returned.
Encryptor::process() [2]
Encrypt the next message chunk, using separate input/output containers (std::vector).
bool process(
const std::vector<uint8_t> &input,
std::vector<uint8_t> &output
);
Parameters:
-
input
A reference to thestd::vector<uint8_t>instance containing the next chunk of the plaintext to be encrypted. This can be arbitrary binary data, e.g. UTF-8 encoded text. NULL bytes are not treated specially. -
output
A reference to thestd::vector<uint8_t>instance where the ciphertext that corresponds to the given plaintext will be stored.The
output.size()must be greater than or equal toinput.size(). If theoutput.size()is larger than theinput.size(), then only the firstinput.size()elements ofoutputwill be filled with encrypted data!
Return value:
- If successful,
trueis returned; otherwisefalseis returned. The function fails, if the outputstd::vectoris too small.
Encryptor::inplace() [1]
Encrypt the next message chunk, using a single buffer.
bool inplace(
uint8_t *const buffer,
size_t length
);
Parameters:
-
buffer
A pointer to the buffer initially containing the next chunk of the plaintext to be encrypted. The plaintext is given as a byte array (uint8_t). This can be arbitrary binary data, e.g. UTF-8 encoded text. NULL bytes are not treated specially. The ciphertext chunk that corresponds to the given plaintext chunk will be stored to the same buffer, thus replacing the plaintext data.The buffer must initially contain at least
lengthbytes of input data; the firstlengthbytes of the buffer will be overwritten with the encrypted data. If the buffer is longer thanlengthbytes, then only the firstlengthbytes will be processed and overwritten. -
length
The length of the plaintext chunk initially contained in the input/output buffer given by thebufferparameter, in bytes. At the same time, this determines the portion of the input/output buffer that will be overwritten with encrypted data, in bytes.Note: It is recommended to process chunks of at least ∼64 KB each, in order to take full advantage of multi-threading.
Return value:
- If successful,
trueis returned; otherwisefalseis returned.
Encryptor::inplace() [2]
Encrypt the next message chunk, using a single container (std::vector).
bool inplace(
std::vector<uint8_t> &buffer
);
Parameters:
buffer
A reference to thestd::vector<uint8_t>initially containing the next chunk of the plaintext to be encrypted. This can be arbitrary binary data, e.g. UTF-8 encoded text. NULL bytes are not treated specially. The ciphertext chunk that corresponds to the given plaintext chunk will be stored to the samestd::vector<uint8_t>, thus replacing all the plaintext data.
Return value:
- If successful,
trueis returned; otherwisefalseis returned.
Encryptor::get_nonce()
Retrieve the random nonce that is used to encrypt the message.
uint64_t get_nonce();
Return value:
-
Returns the nonce that is used to encrypt the message. The purpose of the nonce is to ensure that each message will be encrypted differently, even when the same password is used to encrypt multiple (possibly identical) messages. Therefore, a new random nonce must be chosen for each message! It is not necessary to keep the nonce confidential, but the same nonce must be used for both, encryption and decryption. Typically, the nonce is stored/transmitted alongside the ciphertext.
Note: The
Encryptorclass automatically generates a new, random nonce for each message to be encrypted. Use this function to retrieve that nonce, so that it can be passed toDecryptorfor decryption later.
Decryptor
Class for decrypting data using the SlunkCrypt library.
Constructor
Create and initialize a new Decryptor instance.
Decryptor::Decryptor(
const std::string &passwd,
const uint64_t nonce,
const size_t thread_count = 0U,
const bool legacy_compat = false,
const bool debug_logging = false
);
Parameters:
-
passwd
The password to "protect" the message. The password is given as anstd::string, e.g. UTF-8 encoded characters. The same password may be used to encrypt multiple messages. Also, the same password must be used for both, encryption and decryption; it will only be possible decrypt the ciphertext, if the "correct" password is known. The password must be kept confidential under all circumstances!Note: In order to thwart brute force attacks, it is recommended to choose a "random" password that is at least 12 characters in length and that consists of upper-case characters, lower-case characters, digits as well as other "special" characters.
-
nonce
The nonce (number used once) to be used for the decryption process. The purpose of the nonce is to ensure that each message will be encrypted differently, even when the same password is used to encrypt multiple (possibly identical) messages. Therefore, a new random nonce must be chosen for each message! It is not necessary to keep the nonce confidential, but the same nonce must be used for both, encryption and decryption. Typically, the nonce is stored/transmitted alongside the ciphertext.Note: The
Encryptorclass automatically generates a new, random nonce for each message to be encrypted. UseEncryptor::get_nonce()to retrieve that nonce, so that it can be passed toDecryptorfor decryption later. -
thread_count
Specifies the number of worker threads to use (optional). By default, SlunkCrypt detects the number of available processors and creates one thread for each processor. -
legacy_compat
Enables "legacy" compatibility-mode; required to decrypt messages that were encrypted with SlunkCrypt version 1.2.x or earlier. Option is disabled by default. -
debug_logging
Enables additional debug logging. Messages are written to the syslog (Unix-like) or to the debugger (Windows). Option is disabled by default.
Exceptions:
- Throws
std::runtime_error, if the SlunkCrypt context could not be allocated.
Decryptor::process() [1]
Decrypt the next message chunk, using separate input/output buffers.
bool process(
const uint8_t *const input,
uint8_t *const output,
size_t length
);
Parameters:
-
input
A pointer to the input buffer containing the next chunk of the ciphertext to be decrypted. The ciphertext is given as a byte array (uint8_t).The input buffer must contain at least
lengthbytes of data. If the buffer is longer thanlengthbytes, then only the firstlengthbytes will be processed and the remainder is ignored! -
output
A pointer to the output buffer where the plaintext chunk that corresponds to the given ciphertext chunk will be stored. The plaintext is stored as a byte array (uint8_t); it has the same length as the ciphertext data.The output buffer must provide sufficient space for storing at least
lengthbytes of decrypted data. If the buffer is longer thanlengthbytes, then only the firstlengthbytes of the buffer will be filled with decrypted data! -
length
The length of the ciphertext chunk contained in the input buffer given by theinputparameter, in bytes. At the same time, this determines the minimum required size of the output buffer given by theoutputparameters, in bytes.Note: It is recommended to process chunks of at least ∼64 KB each, in order to take full advantage of multi-threading.
Return value:
- If successful,
trueis returned; otherwisefalseis returned.
Decryptor::process() [2]
Decrypt the next message chunk, using separate input/output containers (std::vector).
bool process(
const std::vector<uint8_t> &input,
std::vector<uint8_t> &output
);
Parameters:
-
input
A reference to thestd::vector<uint8_t>instance containing the next chunk of the ciphertext to be decrypted. -
output
A reference to thestd::vector<uint8_t>instance where the plaintext that corresponds to the given ciphertext will be stored.The
output.size()must be greater than or equal toinput.size(). If theoutput.size()is greater than theinput.size(), then only the firstinput.size()elements ofoutputwill be filled with decrypted data!
Return value:
- If successful,
trueis returned; otherwisefalseis returned. The function fails, if the outputstd::vectoris too small.
Decryptor::inplace() [1]
Decrypt the next message chunk, using a single buffer.
bool inplace(
uint8_t *const buffer,
size_t length
);
Parameters:
-
buffer
A pointer to the buffer initially containing the next chunk of the ciphertext to be decrypted. The ciphertext is given as a byte array (uint8_t). The plaintext that corresponds to the given ciphertext will be stored to the same buffer, replacing the plaintext data.The buffer must initially contain at least
lengthbytes of input data; the firstlengthbytes of the buffer will be overwritten with the encrypted data. If the buffer is longer thanlengthbytes, then only the firstlengthbytes will be processed and overwritten. -
length
The length of the ciphertext chunk initially contained in the input/output buffer given by thebufferparameter, in bytes. At the same time, this determines the portion of the input/output buffer that will be overwritten with decrypted data, in bytes.Note: It is recommended to process chunks of at least ∼64 KB each, in order to take full advantage of multi-threading.
Return value:
- If successful,
trueis returned; otherwisefalseis returned.
Decryptor::inplace() [2]
Decrypt the next message chunk, using a single container (std::vector).
bool inplace(
std::vector<uint8_t> &buffer
);
Parameters:
buffer
A reference to thestd::vector<uint8_t>initially containing the next chunk of the ciphertext to be decrypted. The plaintext that corresponds to the given ciphertext will be stored to the samestd::vector<uint8_t>, replacing all the ciphertext data.
Return value:
- If successful,
trueis returned; otherwisefalseis returned.
C99 API
This section describes the "low-level" C99 API of the SlunkCypt library.
Functions
The SlunkCypt library defines the following functions:
slunkcrypt_alloc()
Allocate and initialize a new SlunkCrypt encryption/decryption context.
slunkcrypt_t slunkcrypt_alloc(
const uint64_t nonce,
const uint8_t *const passwd,
const size_t passwd_len,
const int mode
);
Parameters:
-
nonce
The nonce (number used once) to be used for the encryption/decryption process. The purpose of the nonce is to ensure that each message will be encrypted differently, even when the same password is used to encrypt multiple (possibly identical) messages. Therefore, a new random nonce must be chosen for each message to be encrypted! It is not necessary to keep the nonce confidential, but the same nonce must be used for both, encryption and decryption. Typically, the nonce is stored/transmitted alongside the ciphertext.Note: It is recommended to generate a random nonce via the
slunkcrypt_generate_nonce()function for each message! -
passwd
The password to "protect" the message. The password is given as a byte array (uint8_t), e.g. UTF-8 encoded characters; a terminating NULL character is not required, as the length of the password is specified explicitly. The same password may be used to encrypt multiple messages. Also, the same password must be used for both, encryption and decryption; it will only be possible decrypt the ciphertext, if the "correct" password is known. The password must be kept confidential under all circumstances!Note: In order to thwart brute force attacks, it is recommended to choose a "random" password that is at least 12 characters in length and that consists of upper-case characters, lower-case characters, digits as well as other "special" characters.
-
passwd_len
The length of password given by thepasswdparameter, in bytes, not counting a terminating NULL character. The minimum/maximum length of the password are given by theSLUNKCRYPT_PWDLEN_MINandSLUNKCRYPT_PWDLEN_MAXconstants, respectively. -
mode
The mode of operation. UseSLUNKCRYPT_ENCRYPTin order to set up this context for encryption, or useSLUNKCRYPT_DECRYPTin order to set up this context for decryption.
Return value:
-
If successful, a handle to the new SlunkCrypt context is return; otherwise
SLUNKCRYPT_NULLis returned.Note: Applications should treat
slunkcrypt_tas an opaque handle type. Also, as soon as the SlunkCrypt context is not needed anymore, the application shall callslunkcrypt_free()in order to "erase" and de-allocate that context. If a SlunkCrypt context is not de-allocated properly, it will result in a memory leak!
slunkcrypt_alloc_ext()
Allocate and initialize a new SlunkCrypt encryption/decryption context with additional parameters.
slunkcrypt_t slunkcrypt_alloc_ext(
const uint64_t nonce,
const uint8_t *const passwd,
const size_t passwd_len,
const int mode,
const slunkparam_t *const param
);
Parameters:
-
nonce
The nonce (number used once) to be used for the encryption/decryption process. The purpose of the nonce is to ensure that each message will be encrypted differently, even when the same password is used to encrypt multiple (possibly identical) messages. Therefore, a new random nonce must be chosen for each message to be encrypted! It is not necessary to keep the nonce confidential, but the same nonce must be used for both, encryption and decryption. Typically, the nonce is stored/transmitted alongside the ciphertext.Note: It is recommended to generate a random nonce via the
slunkcrypt_generate_nonce()function for each message! -
passwd
The password to "protect" the message. The password is given as a byte array (uint8_t), e.g. UTF-8 encoded characters; a terminating NULL character is not required, as the length of the password is specified explicitly. The same password may be used to encrypt multiple messages. Also, the same password must be used for both, encryption and decryption; it will only be possible decrypt the ciphertext, if the "correct" password is known. The password must be kept confidential under all circumstances!Note: In order to thwart brute force attacks, it is recommended to choose a "random" password that is at least 12 characters in length and that consists of upper-case characters, lower-case characters, digits as well as other "special" characters.
-
passwd_len
The length of password given by thepasswdparameter, in bytes, not counting a terminating NULL character. The minimum/maximum length of the password are given by theSLUNKCRYPT_PWDLEN_MINandSLUNKCRYPT_PWDLEN_MAXconstants, respectively. -
mode
The mode of operation. UseSLUNKCRYPT_ENCRYPTin order to set up this context for encryption, or useSLUNKCRYPT_DECRYPTin order to set up this context for decryption. -
param
Additional parameters used to initialize the SlunkCrypt context, given as a pointer to aslunkparam_tstruct. The memory for the struct must be allocated by the caller and SlunkCrypt does not take owner ship of this memory; it will copy the relevant fields. The caller is responsible to free the struct; it can be allocated with automatic storage duration.
Return value:
-
If successful, a handle to the new SlunkCrypt context is return; otherwise
SLUNKCRYPT_NULLis returned.Note: Applications should treat
slunkcrypt_tas an opaque handle type. Also, as soon as the SlunkCrypt context is not needed anymore, the application shall callslunkcrypt_free()in order to "erase" and de-allocate that context. If a SlunkCrypt context is not de-allocated properly, it will result in a memory leak!
slunkcrypt_reset()
Re-initialize an existing SlunkCrypt encryption/decryption context.
int slunkcrypt_reset(
const slunkcrypt_t context,
const uint64_t nonce,
const uint8_t *const passwd,
const size_t passwd_len,
const int mode
);
Parameters:
-
context
The existing SlunkCrypt context to be re-initialized. This must be a valid handle that was returned by a previous invocation of theslunkcrypt_alloc()function. -
other parameters:
Please refer to theslunkcrypt_alloc()function for details!
Return value:
- If successful,
SLUNKCRYPT_SUCCESSis returned; otherwiseSLUNKCRYPT_FAILUREorSLUNKCRYPT_ABORTEDis returned.
slunkcrypt_free()
De-allocate an existing SlunkCrypt encryption/decryption context. This will "clear" and release any memory occupied by the context.
void slunkcrypt_free(
const slunkcrypt_t context
);
Parameters:
-
context
The existing SlunkCrypt context to be de-allocated. This must be a valid handle that was returned by a previous invocation of theslunkcrypt_alloc()function.Note: Once a handle has been passed to this function, that handle is invalidated and must not be used again!
slunkcrypt_generate_nonce()
Generate a new random nonce (number used once), using the system's "cryptographically secure" entropy source.
int slunkcrypt_generate_nonce(
int64_t *const nonce
);
Parameters:
nonce
A pointer to a variable of typeint64_tthat receives the new random nonce.
Return value:
- If successful,
SLUNKCRYPT_SUCCESSis returned; otherwiseSLUNKCRYPT_FAILUREorSLUNKCRYPT_ABORTEDis returned.
slunkcrypt_process()
Encrypt or decrypt the next message chunk, using separate input/output buffers.
int slunkcrypt_process(
const slunkcrypt_t context,
const uint8_t *const input,
uint8_t *const output,
size_t length
);
Parameters:
-
context
The existing SlunkCrypt context to be used for processing the message chunk. This context will be updated.Note: This function operates either in "encryption" mode or in "decryption" mode, depending on how the given SlunkCrypt context has been initialized or re-initialized.
-
input
A pointer to the input buffer containing the next chunk of the plaintext to be encrypted (encryption mode), or the next chunk of the ciphertext to be decrypted (decryption mode). The input data is given as a byte array (uint8_t). This can be arbitrary binary data, e.g. UTF-8 encoded text. NULL bytes are not treated specially by this function.The input buffer must contain at least
lengthbytes of data. If the buffer is longer thanlengthbytes, then only the firstlengthbytes will be processed; the remainder is ignored! -
output
A pointer to the output buffer where the ciphertext that corresponds to the given plaintext chunk (encryption mode), or the plaintext that corresponds to the given ciphertext chunk (decryption mode) will be stored. The output data is stored as a byte array (uint8_t) and it always has the same length as the input data.The output buffer must provide sufficient space for storing at least
lengthbytes. If the buffer is longer thanlengthbytes, then only the firstlengthbytes will be filled! -
length
The length of the given plaintext chunk (encryption mode), or the length of the given ciphertext chunk (decryption mode) in theinputbuffer, in bytes. At the same time, this parameter determines the minimum required size of theoutputbuffer, in bytes. If this parameter is set to zero, the function does nothing; this is not considered an error.Note: It is recommended to process chunks of at least ∼64 KB each, in order to take full advantage of multi-threading.
Return value:
- If successful,
SLUNKCRYPT_SUCCESSis returned; otherwiseSLUNKCRYPT_FAILUREorSLUNKCRYPT_ABORTEDis returned.
slunkcrypt_inplace()
Encrypt or decrypt the next message chunk, using a single input/output buffer.
int slunkcrypt_inplace(
const slunkcrypt_t context,
uint8_t *const buffer,
size_t length
);
Parameters:
-
context
The existing SlunkCrypt context to be used for processing the message chunk. This context will be updated.Note: This function operates either in "encryption" mode or in "decryption" mode, depending on how the given SlunkCrypt context has been initialized or re-initialized.
-
buffer
A pointer to the buffer containing the next chunk of the plaintext to be encrypted (encryption mode), or the next chunk of the ciphertext to be decrypted (decryption mode). The input data is given as a byte array (uint8_t). This can be arbitrary binary data, e.g. UTF-8 encoded text. NULL bytes are not treated specially by this function. The ciphertext that corresponds to the given plaintext chunk (encryption mode), or the plaintext that corresponds to the given ciphertext chunk (decryption mode) will be stored to the same buffer.The given buffer must initially contain at least
lengthbytes of input data. The firstlengthbytes in the buffer will be processed and will be overwritten with the corresponding output data. If the buffer is longer thanlengthbytes, then only the firstlengthbytes in the buffer will be processed; the remainder is ignored! -
length
The length of the plaintext chunk (encryption mode), or the length of the ciphertext chunk (decryption mode) initially contained in the input/output buffer, in bytes.Note: It is recommended to process chunks of at least ∼64 KB each, in order to take full advantage of multi-threading.
Return value:
- If successful,
SLUNKCRYPT_SUCCESSis returned; otherwiseSLUNKCRYPT_FAILUREorSLUNKCRYPT_ABORTEDis returned.
slunkcrypt_random_bytes()
Generate a sequence of random bytes, using the system's "cryptographically secure" entropy source.
size_t slunkcrypt_random_bytes(
uint8_t *const buffer,
const size_t length
);
Parameters:
-
buffer
A pointer to the output buffer where the random bytes will be stored.The output buffer must provide sufficient space for storing at least
lengthbytes of random data. At most the firstlengthbytes of the buffer will be filled with random data! -
length
The number of random bytes to be generated. At the same time, this parameter determines the minimum required size of theoutputbuffer, in bytes.
Return value:
-
The number of random bytes that have been generated and that have been stored to the
outputbuffer buffer is returned.The number of generated random bytes can be at most
length. Less thanlengthrandom bytes will be generated, if and only if the the system's "cryptographically secure" entropy source could not provide the requested number of bytes at this time – in that case, you can try again later. The number of generated bytes can be as low as 0.
slunkcrypt_bzero()
Erase the contents of a byte array, by overwriting it with zero bytes. Compiler optimizations will not remove the erase operation.
void slunkcrypt_bzero(
void *const buffer,
const size_t length
);
Parameters:
-
buffer
A pointer to the buffer whose content is to be erased.The buffer must be at least
lengthbytes in size. If the buffer is longer thanlengthbytes, then only the firstlengthbytes of the buffer will be erased! -
length
The size of the buffer to be erased, in bytes.
Types
SlunkCrypt parameters
The slunkparam_t struct is used to pass additional parameters that will be used for initializing the SlunkCrypt context. It contains the following fields:
version– The version of the parameter struct; must be set toSLUNKCRYPT_PARAM_VERSION.thread_count– The number of worker threads to use. If this parameter is set to 0, which is the default value, then SlunkCrypt automatically detects the number of available (logical) processors and creates one thread for each processor. Also, the number of threads is capped to a maximum ofMAX_THREADS(currently defined as 32).legacy_compat– If set toSLUNKCRYPT_TRUE, enables "legacy" compatibility-mode; required to decrypt messages that were encrypted with SlunkCrypt version 1.2.x or earlier.debug_logging– If set toSLUNKCRYPT_TRUE, enables additional debug logging; messages are written to the syslog (Unix-like) or to the debugger (Windows).
Global variables
The SlunkCypt library defines the following global variables:
Version information
These variables can be used to determine the version of the SlunkCrypt library at runtime, using the semantic versioning scheme:
const uint16_t SLUNKCRYPT_VERSION_MAJOR– The current major version.const uint16_t SLUNKCRYPT_VERSION_MINOR– The current minor version.const uint16_t SLUNKCRYPT_VERSION_PATCH– The current patch version.const char *SLUNKCRYPT_BUILD– The build date and time, as a C string, in the"mmm dd yyyy, hh:mm:ss"format.
Abort request
If this flag is set to a non-zero value by the application, any ongoing SlunkCypt library invocation will be aborted as quickly as possible:
-
volatile int g_slunkcrypt_abort_flag– The global abort flag.Note: Applications may set this flag in their signal handler, e.g. when a
SIGINTis received, in order to "gracefully" shut down the SlunkCypt library. All long-running library functions will returnSLUNKCRYPT_ABORTED, if the invocation was interrupted. The application still is responsible for free'ing any SlunkCypt contexts that it allocated successfully!
Constants
The SlunkCypt library defines the following constants:
Mode of operation
The SlunkCypt library supports the following modes of operation:
SLUNKCRYPT_ENCRYPT– Run library in encryption mode, i.e. consume plaintext and produce ciphertext.SLUNKCRYPT_DECRYPT– Run library in decryption mode, i.e. consume ciphertext and produce plaintext.
Limits
The following limits are defined for the SlunkCypt library:
SLUNKCRYPT_PWDLEN_MIN– The minimum required length of a password, currently 8 bytes.SLUNKCRYPT_PWDLEN_MAX– The maximum allowed length of a password, currently 256 bytes.
Error codes
SlunkCypt library functions that return an error code may return one of the following constants:
SLUNKCRYPT_SUCCESS– The operation completed successfully.SLUNKCRYPT_FAILURE– The operation has failed.SLUNKCRYPT_ABORTED– The operation was aborted before completion, as requested by the application.
Thread safety
The following functions are fully "thread-safe" and thus may safely be called by any thread at any time without the need for synchronization:
slunkcrypt_alloc()slunkcrypt_generate_nonce()slunkcrypt_random_bytes()slunkcrypt_bzero()Encryptor::Encryptor()Decryptor::Decryptor()
The following functions are "reentrant" and thus may safely be called by any thread at any time without the need for synchronization – provided that each instance of slunkcrypt_t, Encryptor or Decryptor is "owned" by a single thread and that each instance will exclusively be access by its respective "owner" thread:
slunkcrypt_reset()slunkcrypt_free()slunkcrypt_process()slunkcrypt_inplace()Encryptor::process()Encryptor::inplace()Encryptor::get_nonce()Decryptor::process()Decryptor::inplace()
Note: If the same slunkcrypt_t, Encryptor or Decryptor instance needs to be shared across multiple threads (i.e. the same instance is accessed by concurrent threads), then the application must serialize any invocation of the above functions on that shared instance, by using a suitable synchronization mechanism! This can be achieved by using a mutex.
Source Code
The latest SlunkCrypt source code is available from the official Git mirrors at:
- https://gitlab.com/lord_mulder/slunkcrypt/
- https://bitbucket.org/muldersoft/slunkcrypt/
- https://repo.or.cz/slunkcrypt.git
- https://punkindrublic.mooo.com:3000/Muldersoft/SlunkCrypt
Deprecated mirror sites:
Build Instructions
SlunkCrypt can be built from the sources on Microsoft Windows or any POSIX-compatible platform, using a C-compiler that supports the C99 standard.
-
Microsoft Windows:
Project/solution files for Visual Studio are provided. These should work “out of the box” with Visual Studio 2017 or any later version.
Just open the solution, select the “Release” configuration, choose the “x86” or “x64” platform, and finally pressF5.
Visual Studio also is the only way to build the SlunkCrypt GUI, which is based on Microsoft.NET and Windows Presentation Foundation (WPF).Alternatively, SlunkCrypt can built using Mingw-w64 (available via MSYS2) or even Cygwin – see Linux instructions for details!
-
Linux:
Please make sure that the C compiler (GCC or Clang) as well as Make are installed. Then simply runmake -Bfrom the project's base directory!If not already installed, the required build tools can usually be installed via your distribution's package manager.
For example, on Debian-based distributions, the commandsudo apt install build-essentialinstalls all the required build tools at once.In order to create a fully-static binary of SlunkCrypt that runs on any Linux distribution from the last decade, you can use musl libc:
make -B CC=musl-gcc STATIC=1 -
BSD and Solaris:
SlunkCrypt can be built on various BSD flavors and Solaris, but the commandgmake -Bneeds to be used here, since the nativemakedoesn't work!
GNU Make can be installed from the package manager. For example, usepkg install gmakeon FreeBSD orpkg_add gmakeon OpenBSD. -
Mac OS X:
Once you have managed to find a terminal (or even better, connect via SSH), Mac OS X almost works like a proper operating system.
The Xcode command-line tools can be installed with the commandxcode-select --install, if not present yet. Then just typemake -Bto build!Hint: If you want to build with GCC, which produces faster code than Apple's Xcode compiler, you may install it on Mac OS X via Homebrew.
Frequently Asked Questions
-
Why does the decryption of my file fail with a checksum error?
If SlunkCrypt fails to decrypt a file and reports a “checksum mismatch” error, then this means that either the given file was not actually encrypted with SlunkCrypt, the file was corrupted in some kind of way (e.g. incomplete download), or you did not provide the correct passphrase for the file. There is, unfortuantely, no way to distinguish these three cases, as files encrypted with SlunkCrypt are indistingushable from random noise – only with the correct passphrase, some meaningful data can be restored from the encrypted file. Trying to decrypt the file with a wrong passphrase results in just "random" gibberish! However, the same also happens if the file was corrupted, or if the file was not encrypted with SlunkCrypt.
Note: If you are using SlunkCrypt 1.3.0 or later, then files that have been encrypted with SlunkCrypt 1.2.x or older can only be decrypted by enabling the “legacy” compatibility-mode!
-
How can I recover the lost passphrase for my file?
SlunkCrypt uses a combination of the given passphrase and the individual nonce to encrypt each file in a unique (pseudo-random) way. This means that no two files are encrypted in the same way. Consequently, the decryption of the file is only possible using the correct passphrase, i.e. the one which was used to encrypt the file. Trying to decrypt the file with a wrong passphrase results in just "random" gibberish. And, for good reasons, there is no way to recover the passphrase from an encrypted file, so take good care of your passphrase!
In theory, it is possible to “crack” the passphrase using the brute-force method, i.e. try out every possible passphrase (up to a certain length) until the correct one is found. However, provided that a sufficiently long and random passphrase was chosen – which is highly recommended – there are way too many combinations to try them all, in a reasonable time. For example, with a length of 12 characters (ASCII), there are 9512 = 540,360,087,662,636,962,890,625 possible combinations! This renders brute-force attacks practically impossible.
License
This work has been released under the CC0 1.0 Universal license.
For details, please refer to:
https://creativecommons.org/publicdomain/zero/1.0/legalcode
Acknowledgement
SlunkCrypt incorporates code from the following third-party software projects:
-
The "checksum" algorithm used by the SlunkCrypt command-line application was adapted from the BLAKE2 reference C implementation.
BLAKE2 reference source code package - reference C implementations Copyright 2012, Samuel Neves <sneves@dei.uc.pt>. You may use this under the terms of the CC0, the OpenSSL Licence, or the Apache Public License 2.0, at your option. The terms of these licenses can be found at: - CC0 1.0 Universal : http://creativecommons.org/publicdomain/zero/1.0 - OpenSSL license : https://www.openssl.org/source/license.html - Apache 2.0 : http://www.apache.org/licenses/LICENSE-2.0 More information about the BLAKE2 hash function can be found at https://blake2.net. -
Windows only: Builds of SlunkCypt that have multi-threading enabled use the POSIX Threads for Windows (pthreads4w) library.
Pthreads4w - POSIX Threads for Windows Copyright 1998 John E. Bossom Copyright 1999-2018, Pthreads4w contributors Homepage: https://sourceforge.net/projects/pthreads4w/ Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
▮